2026 年 5 月 7 日 23:50 UTC,AWS us-east-1 一栋数据中心机房里多台冷却机同时失效,机柜温度飙升。几分钟后,Coinbase 的现货、Prime、International
和衍生品交易所——几乎全部撮合通道——开始陆续不可用,持续数小时。
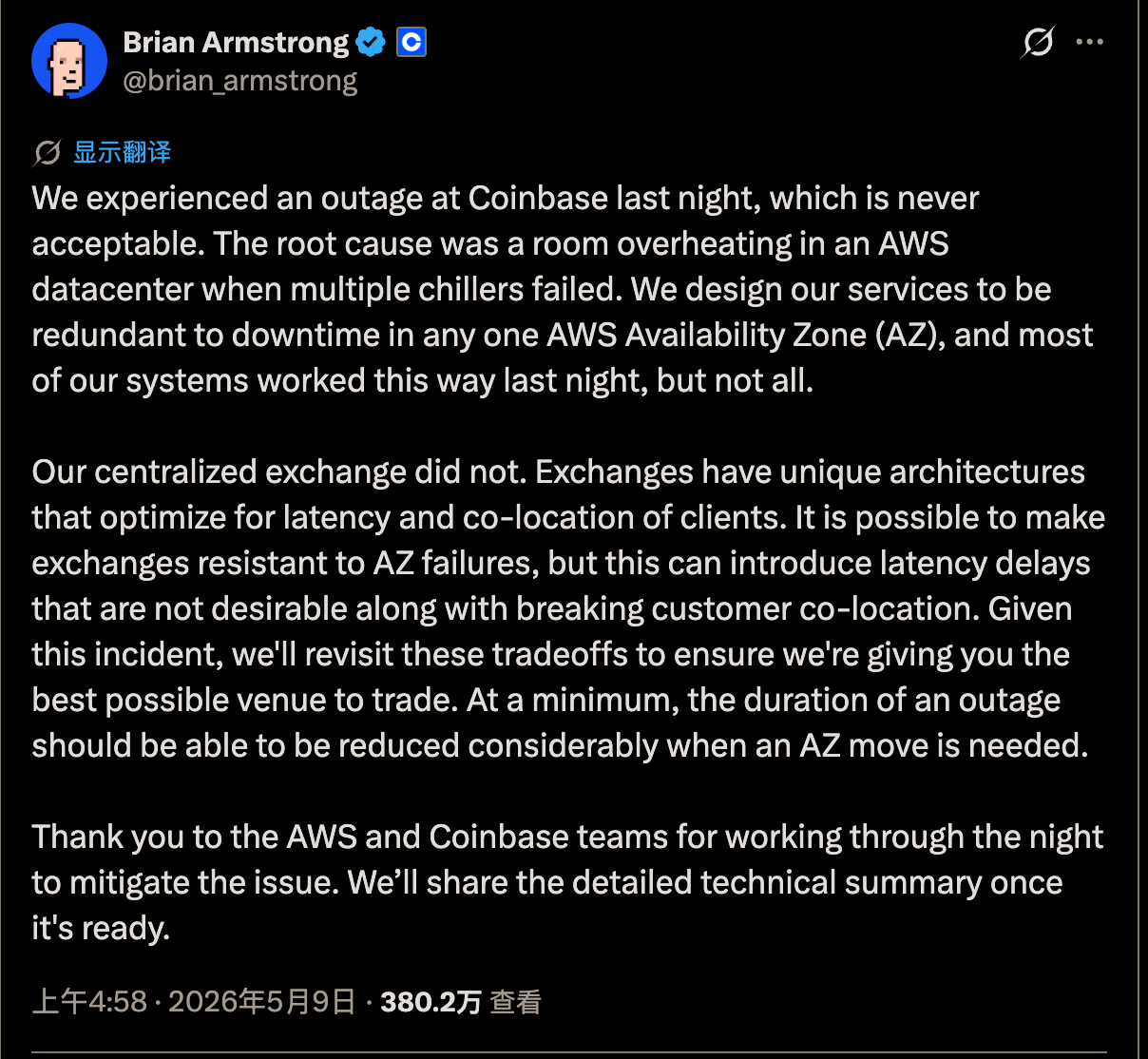
事故第二天,CEO Brian Armstrong 在 X 上简短回应:
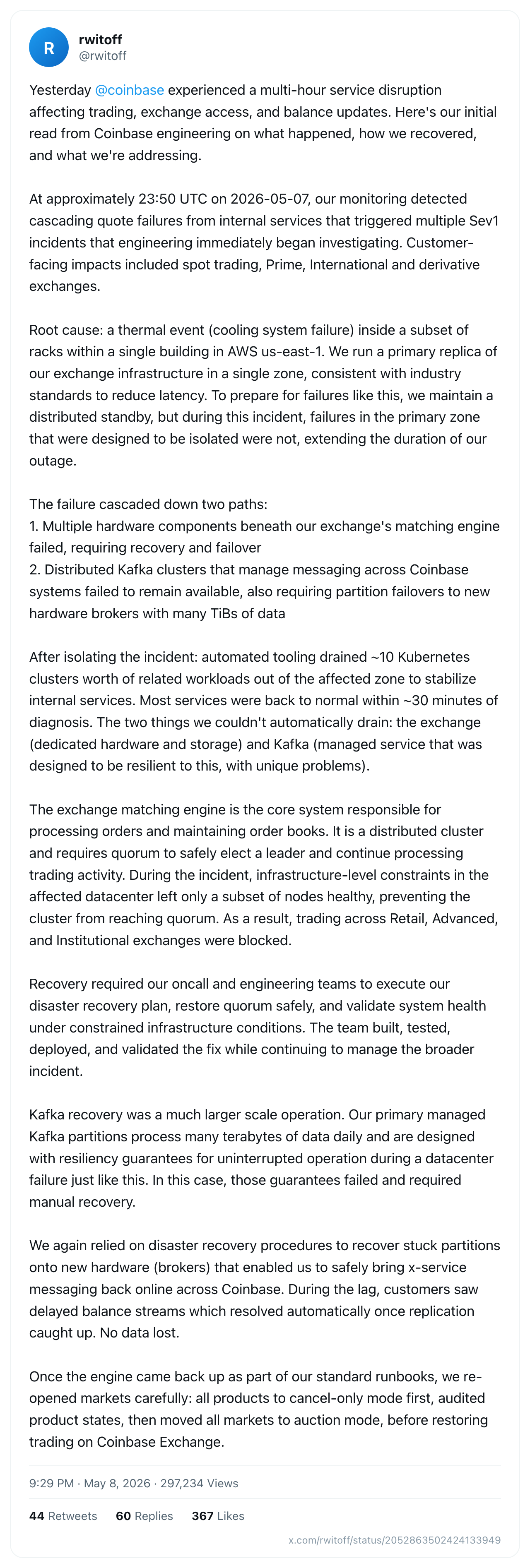
几小时后,Coinbase 工程负责人 @rwitoff 发布了初版技术总结。
要看懂这几个报告,要先了解一下 coinbase 这种公司的架构:
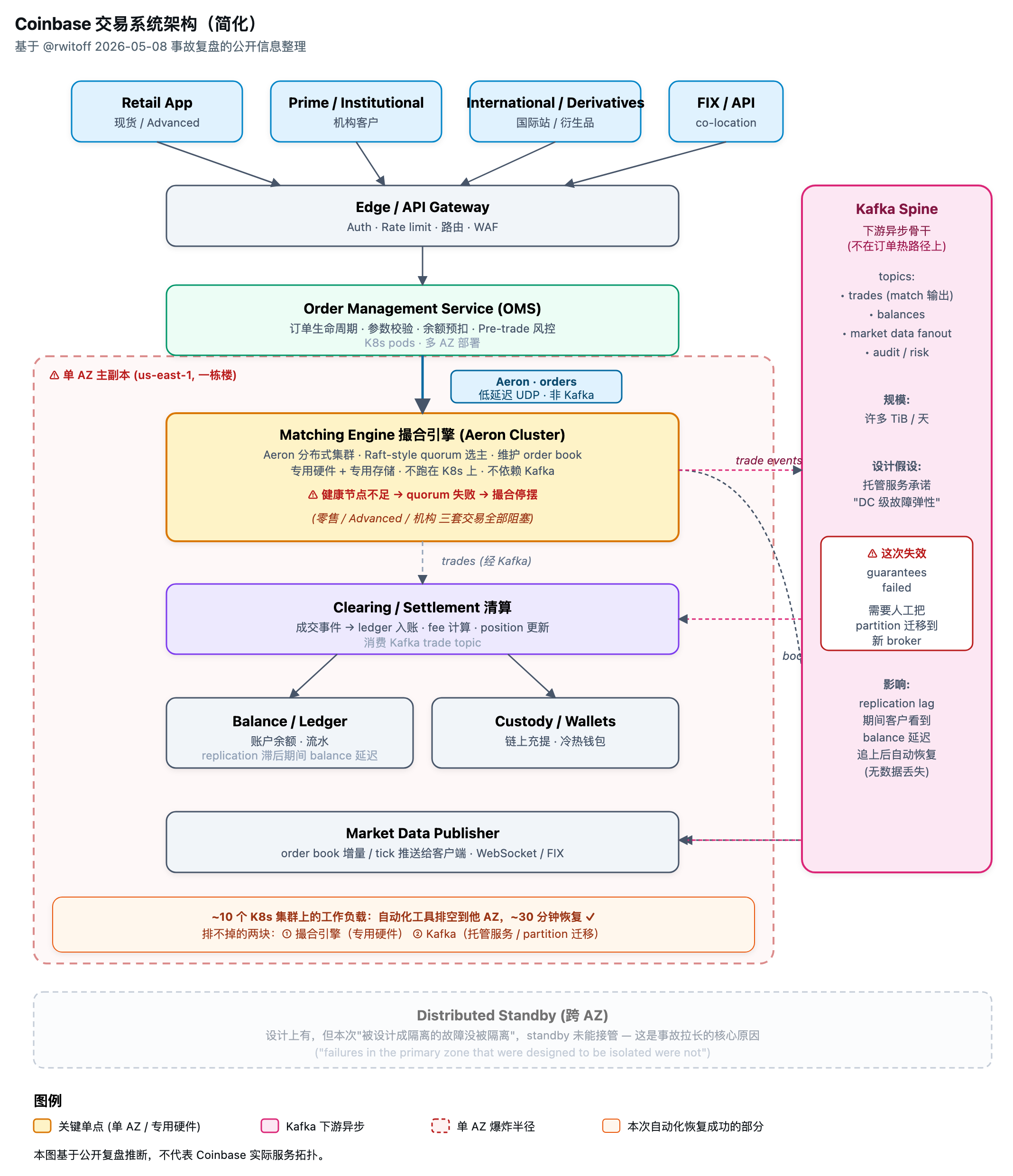
文中提到的撮合引擎使用了 java 的 aeron cluster,这个一个用类 raft 算法实现的集群库,能保证个别副本挂掉时不影响整体集群的功能。
coinbase 大概率买了 aeron 的商业版,所以,aeron 本身在其它 az 还有一个 standby 的备份集群。
交易管理订单和资产在 coinbase 里应该是分了两个模块,一个是 order management system,另一个是清算,图上叫 balance/ledger。
订单成交后,撮合会把成交消息发出来,结果 kafka 集群到 balance/ledger 服务,进而更新用户余额。
这里根据 coinbase 两位高管的公开言论,撮合系统虽然有其它 AZ 的 standby,但是因为不能破坏用户的 colocation,所以不能进行 AZ 切换。这里说明他们的 colocation 程序可能只部署了一份。。。(colocation 其实就是交易所给机构提供的低延迟链路,机构会把自己的做市程序部署上去)。
而 kafka 这一部分就比较奇怪了,工程负责人说他们的 replication factor 是没问题的,那按照常识,这里应该 rf 至少是 3,然后 min.insync.replica 应该是 2。在不考虑成本的情况下,kafka 的三个副本是可以部署在不同的 AZ 的:
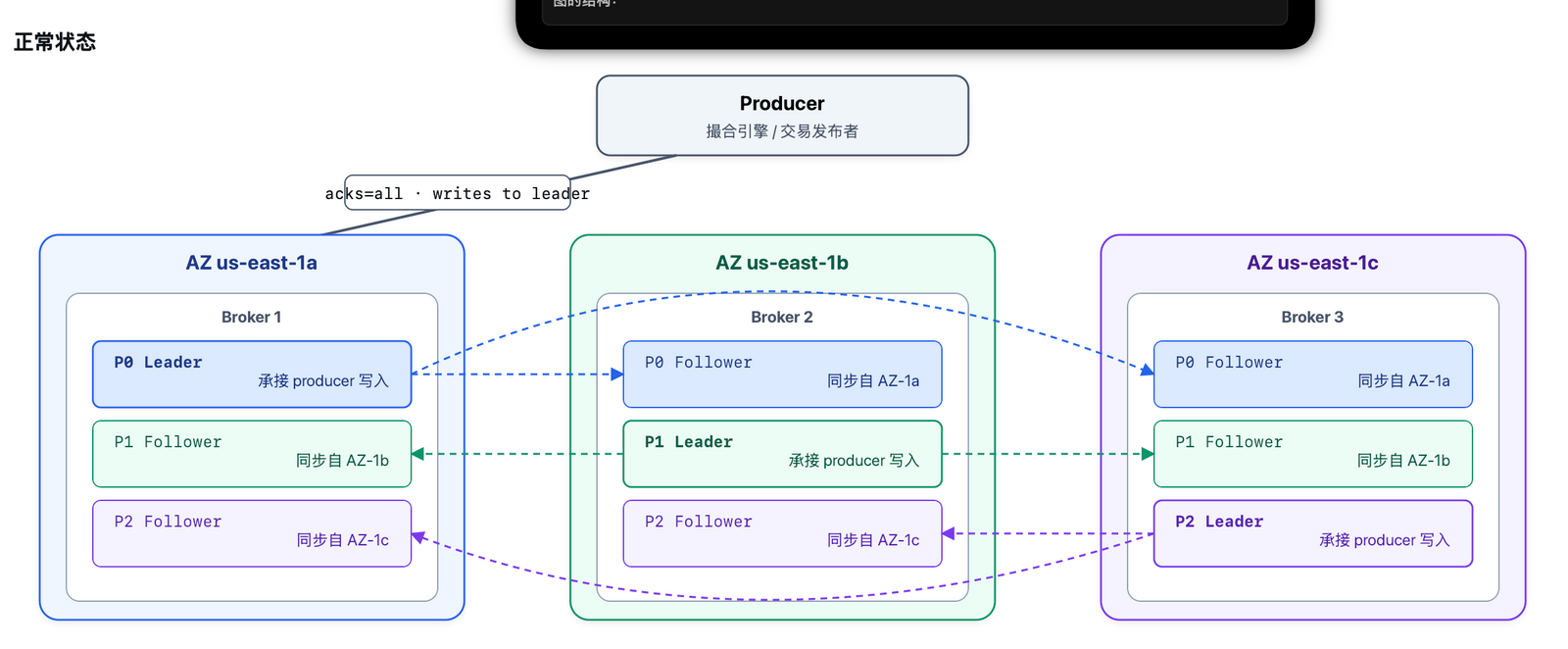
这种情况下,任何一个 AZ 挂了,kafka 只要 leader 切换到可用的 az 就可以。因为清算链路延迟要求没那么高,所以在事故时跨 AZ 也是可以接受的。
但是一般的公司可能不会这么干,因为把三副本部署在三个 AZ 的话,会有高昂的跨 AZ 流量费。
所以很多公司可能会为了节省成本,把两个副本部署在一个 AZ 里,或者三个副本都在一个 AZ 里。
但是按说 coinbase 不是这么穷的公司吧,所以这里就非常奇怪。
